view release on metacpan or search on metacpan
xgboost/cub/cub/block/block_discontinuity.cuh view on Meta::CPAN
* \tparam BLOCK_DIM_Z <b>[optional]</b> The thread block length in threads along the Z dimension (default: 1)
* \tparam PTX_ARCH <b>[optional]</b> \ptxversion
*
* \par Overview
* - A set of "head flags" (or "tail flags") is often used to indicate corresponding items
* that differ from their predecessors (or successors). For example, head flags are convenient
* for demarcating disjoint data segments as part of a segmented scan or reduction.
* - \blocked
*
* \par Performance Considerations
* - \granularity
*
* \par A Simple Example
* \blockcollective{BlockDiscontinuity}
* \par
* The code snippet below illustrates the head flagging of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_discontinuity.cuh>
xgboost/cub/cub/block/block_discontinuity.cuh view on Meta::CPAN
* \brief Sets head flags indicating discontinuities between items partitioned across the thread block, for which the first item has no reference and is always flagged.
*
* \par
* - The flag <tt>head_flags<sub><em>i</em></sub></tt> is set for item
* <tt>input<sub><em>i</em></sub></tt> when
* <tt>flag_op(</tt><em>previous-item</em><tt>, input<sub><em>i</em></sub>)</tt>
* returns \p true (where <em>previous-item</em> is either the preceding item
* in the same thread or the last item in the previous thread).
* - For <em>thread</em><sub>0</sub>, item <tt>input<sub>0</sub></tt> is always flagged.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates the head-flagging of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_discontinuity.cuh>
*
xgboost/cub/cub/block/block_discontinuity.cuh view on Meta::CPAN
*
* \par
* - The flag <tt>head_flags<sub><em>i</em></sub></tt> is set for item
* <tt>input<sub><em>i</em></sub></tt> when
* <tt>flag_op(</tt><em>previous-item</em><tt>, input<sub><em>i</em></sub>)</tt>
* returns \p true (where <em>previous-item</em> is either the preceding item
* in the same thread or the last item in the previous thread).
* - For <em>thread</em><sub>0</sub>, item <tt>input<sub>0</sub></tt> is compared
* against \p tile_predecessor_item.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates the head-flagging of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_discontinuity.cuh>
*
xgboost/cub/cub/block/block_discontinuity.cuh view on Meta::CPAN
*
* \par
* - The flag <tt>tail_flags<sub><em>i</em></sub></tt> is set for item
* <tt>input<sub><em>i</em></sub></tt> when
* <tt>flag_op(input<sub><em>i</em></sub>, </tt><em>next-item</em><tt>)</tt>
* returns \p true (where <em>next-item</em> is either the next item
* in the same thread or the first item in the next thread).
* - For <em>thread</em><sub><em>BLOCK_THREADS</em>-1</sub>, item
* <tt>input</tt><sub><em>ITEMS_PER_THREAD</em>-1</sub> is always flagged.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates the tail-flagging of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_discontinuity.cuh>
*
xgboost/cub/cub/block/block_discontinuity.cuh view on Meta::CPAN
* \par
* - The flag <tt>tail_flags<sub><em>i</em></sub></tt> is set for item
* <tt>input<sub><em>i</em></sub></tt> when
* <tt>flag_op(input<sub><em>i</em></sub>, </tt><em>next-item</em><tt>)</tt>
* returns \p true (where <em>next-item</em> is either the next item
* in the same thread or the first item in the next thread).
* - For <em>thread</em><sub><em>BLOCK_THREADS</em>-1</sub>, item
* <tt>input</tt><sub><em>ITEMS_PER_THREAD</em>-1</sub> is compared
* against \p tile_successor_item.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates the tail-flagging of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_discontinuity.cuh>
*
xgboost/cub/cub/block/block_discontinuity.cuh view on Meta::CPAN
* in the same thread or the last item in the previous thread).
* - For <em>thread</em><sub>0</sub>, item <tt>input<sub>0</sub></tt> is always flagged.
* - The flag <tt>tail_flags<sub><em>i</em></sub></tt> is set for item
* <tt>input<sub><em>i</em></sub></tt> when
* <tt>flag_op(input<sub><em>i</em></sub>, </tt><em>next-item</em><tt>)</tt>
* returns \p true (where <em>next-item</em> is either the next item
* in the same thread or the first item in the next thread).
* - For <em>thread</em><sub><em>BLOCK_THREADS</em>-1</sub>, item
* <tt>input</tt><sub><em>ITEMS_PER_THREAD</em>-1</sub> is always flagged.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates the head- and tail-flagging of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_discontinuity.cuh>
*
xgboost/cub/cub/block/block_discontinuity.cuh view on Meta::CPAN
* - For <em>thread</em><sub>0</sub>, item <tt>input<sub>0</sub></tt> is always flagged.
* - The flag <tt>tail_flags<sub><em>i</em></sub></tt> is set for item
* <tt>input<sub><em>i</em></sub></tt> when
* <tt>flag_op(input<sub><em>i</em></sub>, </tt><em>next-item</em><tt>)</tt>
* returns \p true (where <em>next-item</em> is either the next item
* in the same thread or the first item in the next thread).
* - For <em>thread</em><sub><em>BLOCK_THREADS</em>-1</sub>, item
* <tt>input</tt><sub><em>ITEMS_PER_THREAD</em>-1</sub> is compared
* against \p tile_predecessor_item.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates the head- and tail-flagging of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_discontinuity.cuh>
*
xgboost/cub/cub/block/block_discontinuity.cuh view on Meta::CPAN
* - For <em>thread</em><sub>0</sub>, item <tt>input<sub>0</sub></tt> is compared
* against \p tile_predecessor_item.
* - The flag <tt>tail_flags<sub><em>i</em></sub></tt> is set for item
* <tt>input<sub><em>i</em></sub></tt> when
* <tt>flag_op(input<sub><em>i</em></sub>, </tt><em>next-item</em><tt>)</tt>
* returns \p true (where <em>next-item</em> is either the next item
* in the same thread or the first item in the next thread).
* - For <em>thread</em><sub><em>BLOCK_THREADS</em>-1</sub>, item
* <tt>input</tt><sub><em>ITEMS_PER_THREAD</em>-1</sub> is always flagged.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates the head- and tail-flagging of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_discontinuity.cuh>
*
xgboost/cub/cub/block/block_discontinuity.cuh view on Meta::CPAN
* against \p tile_predecessor_item.
* - The flag <tt>tail_flags<sub><em>i</em></sub></tt> is set for item
* <tt>input<sub><em>i</em></sub></tt> when
* <tt>flag_op(input<sub><em>i</em></sub>, </tt><em>next-item</em><tt>)</tt>
* returns \p true (where <em>next-item</em> is either the next item
* in the same thread or the first item in the next thread).
* - For <em>thread</em><sub><em>BLOCK_THREADS</em>-1</sub>, item
* <tt>input</tt><sub><em>ITEMS_PER_THREAD</em>-1</sub> is compared
* against \p tile_successor_item.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates the head- and tail-flagging of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_discontinuity.cuh>
*
xgboost/cub/cub/block/block_histogram.cuh view on Meta::CPAN
* \tparam PTX_ARCH <b>[optional]</b> \ptxversion
*
* \par Overview
* - A <a href="http://en.wikipedia.org/wiki/Histogram"><em>histogram</em></a>
* counts the number of observations that fall into each of the disjoint categories (known as <em>bins</em>).
* - BlockHistogram can be optionally specialized to use different algorithms:
* -# <b>cub::BLOCK_HISTO_SORT</b>. Sorting followed by differentiation. [More...](\ref cub::BlockHistogramAlgorithm)
* -# <b>cub::BLOCK_HISTO_ATOMIC</b>. Use atomic addition to update byte counts directly. [More...](\ref cub::BlockHistogramAlgorithm)
*
* \par Performance Considerations
* - \granularity
*
* \par A Simple Example
* \blockcollective{BlockHistogram}
* \par
* The code snippet below illustrates a 256-bin histogram of 512 integer samples that
* are partitioned across 128 threads where each thread owns 4 samples.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_histogram.cuh>
*
xgboost/cub/cub/block/block_histogram.cuh view on Meta::CPAN
{
histogram[histo_offset + linear_tid] = 0;
}
}
/**
* \brief Constructs a block-wide histogram in shared/device-accessible memory. Each thread contributes an array of input elements.
*
* \par
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a 256-bin histogram of 512 integer samples that
* are partitioned across 128 threads where each thread owns 4 samples.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_histogram.cuh>
*
* __global__ void ExampleKernel(...)
xgboost/cub/cub/block/block_histogram.cuh view on Meta::CPAN
// Composite the histogram
InternalBlockHistogram(temp_storage).Composite(items, histogram);
}
/**
* \brief Updates an existing block-wide histogram in shared/device-accessible memory. Each thread composites an array of input elements.
*
* \par
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a the initialization and update of a
* histogram of 512 integer samples that are partitioned across 128 threads
* where each thread owns 4 samples.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_histogram.cuh>
*
xgboost/cub/cub/block/block_radix_rank.cuh view on Meta::CPAN
* \tparam BLOCK_DIM_Y <b>[optional]</b> The thread block length in threads along the Y dimension (default: 1)
* \tparam BLOCK_DIM_Z <b>[optional]</b> The thread block length in threads along the Z dimension (default: 1)
* \tparam PTX_ARCH <b>[optional]</b> \ptxversion
*
* \par Overview
* Blah...
* - Keys must be in a form suitable for radix ranking (i.e., unsigned bits).
* - \blocked
*
* \par Performance Considerations
* - \granularity
*
* \par Examples
* \par
* - <b>Example 1:</b> Simple radix rank of 32-bit integer keys
* \code
* #include <cub/cub.cuh>
*
* template <int BLOCK_THREADS>
* __global__ void ExampleKernel(...)
* {
xgboost/cub/cub/block/block_radix_sort.cuh view on Meta::CPAN
* ordering of those keys.
* - BlockRadixSort can sort all of the built-in C++ numeric primitive types, e.g.:
* <tt>unsigned char</tt>, \p int, \p double, etc. Within each key, the implementation treats fixed-length
* bit-sequences of \p RADIX_BITS as radix digit places. Although the direct radix sorting
* method can only be applied to unsigned integral types, BlockRadixSort
* is able to sort signed and floating-point types via simple bit-wise transformations
* that ensure lexicographic key ordering.
* - \rowmajor
*
* \par Performance Considerations
* - \granularity
*
* \par A Simple Example
* \blockcollective{BlockRadixSort}
* \par
* The code snippet below illustrates a sort of 512 integer keys that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh>
xgboost/cub/cub/block/block_radix_sort.cuh view on Meta::CPAN
//@} end member group
/******************************************************************//**
* \name Sorting (blocked arrangements)
*********************************************************************/
//@{
/**
* \brief Performs an ascending block-wide radix sort over a [<em>blocked arrangement</em>](index.html#sec5sec3) of keys.
*
* \par
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a sort of 512 integer keys that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive keys.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh>
*
xgboost/cub/cub/block/block_radix_sort.cuh view on Meta::CPAN
/**
* \brief Performs an ascending block-wide radix sort across a [<em>blocked arrangement</em>](index.html#sec5sec3) of keys and values.
*
* \par
* - BlockRadixSort can only accommodate one associated tile of values. To "truck along"
* more than one tile of values, simply perform a key-value sort of the keys paired
* with a temporary value array that enumerates the key indices. The reordered indices
* can then be used as a gather-vector for exchanging other associated tile data through
* shared memory.
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a sort of 512 integer keys and values that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive pairs.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh>
*
xgboost/cub/cub/block/block_radix_sort.cuh view on Meta::CPAN
int begin_bit = 0, ///< [in] <b>[optional]</b> The beginning (least-significant) bit index needed for key comparison
int end_bit = sizeof(KeyT) * 8) ///< [in] <b>[optional]</b> The past-the-end (most-significant) bit index needed for key comparison
{
SortBlocked(keys, values, begin_bit, end_bit, Int2Type<false>(), Int2Type<KEYS_ONLY>());
}
/**
* \brief Performs a descending block-wide radix sort over a [<em>blocked arrangement</em>](index.html#sec5sec3) of keys.
*
* \par
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a sort of 512 integer keys that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive keys.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh>
*
xgboost/cub/cub/block/block_radix_sort.cuh view on Meta::CPAN
/**
* \brief Performs a descending block-wide radix sort across a [<em>blocked arrangement</em>](index.html#sec5sec3) of keys and values.
*
* \par
* - BlockRadixSort can only accommodate one associated tile of values. To "truck along"
* more than one tile of values, simply perform a key-value sort of the keys paired
* with a temporary value array that enumerates the key indices. The reordered indices
* can then be used as a gather-vector for exchanging other associated tile data through
* shared memory.
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a sort of 512 integer keys and values that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive pairs.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh>
*
xgboost/cub/cub/block/block_radix_sort.cuh view on Meta::CPAN
/******************************************************************//**
* \name Sorting (blocked arrangement -> striped arrangement)
*********************************************************************/
//@{
/**
* \brief Performs an ascending radix sort across a [<em>blocked arrangement</em>](index.html#sec5sec3) of keys, leaving them in a [<em>striped arrangement</em>](index.html#sec5sec3).
*
* \par
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a sort of 512 integer keys that
* are initially partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive keys. The final partitioning is striped.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh>
*
xgboost/cub/cub/block/block_radix_sort.cuh view on Meta::CPAN
/**
* \brief Performs an ascending radix sort across a [<em>blocked arrangement</em>](index.html#sec5sec3) of keys and values, leaving them in a [<em>striped arrangement</em>](index.html#sec5sec3).
*
* \par
* - BlockRadixSort can only accommodate one associated tile of values. To "truck along"
* more than one tile of values, simply perform a key-value sort of the keys paired
* with a temporary value array that enumerates the key indices. The reordered indices
* can then be used as a gather-vector for exchanging other associated tile data through
* shared memory.
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a sort of 512 integer keys and values that
* are initially partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive pairs. The final partitioning is striped.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh>
*
xgboost/cub/cub/block/block_radix_sort.cuh view on Meta::CPAN
int end_bit = sizeof(KeyT) * 8) ///< [in] <b>[optional]</b> The past-the-end (most-significant) bit index needed for key comparison
{
SortBlockedToStriped(keys, values, begin_bit, end_bit, Int2Type<false>(), Int2Type<KEYS_ONLY>());
}
/**
* \brief Performs a descending radix sort across a [<em>blocked arrangement</em>](index.html#sec5sec3) of keys, leaving them in a [<em>striped arrangement</em>](index.html#sec5sec3).
*
* \par
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a sort of 512 integer keys that
* are initially partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive keys. The final partitioning is striped.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh>
*
xgboost/cub/cub/block/block_radix_sort.cuh view on Meta::CPAN
/**
* \brief Performs a descending radix sort across a [<em>blocked arrangement</em>](index.html#sec5sec3) of keys and values, leaving them in a [<em>striped arrangement</em>](index.html#sec5sec3).
*
* \par
* - BlockRadixSort can only accommodate one associated tile of values. To "truck along"
* more than one tile of values, simply perform a key-value sort of the keys paired
* with a temporary value array that enumerates the key indices. The reordered indices
* can then be used as a gather-vector for exchanging other associated tile data through
* shared memory.
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a sort of 512 integer keys and values that
* are initially partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive pairs. The final partitioning is striped.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_radix_sort.cuh>
*
xgboost/cub/cub/block/block_reduce.cuh view on Meta::CPAN
* \par Overview
* - A <a href="http://en.wikipedia.org/wiki/Reduce_(higher-order_function)"><em>reduction</em></a> (or <em>fold</em>)
* uses a binary combining operator to compute a single aggregate from a list of input elements.
* - \rowmajor
* - BlockReduce can be optionally specialized by algorithm to accommodate different latency/throughput workload profiles:
* -# <b>cub::BLOCK_REDUCE_RAKING_COMMUTATIVE_ONLY</b>. An efficient "raking" reduction algorithm that only supports commutative reduction operators. [More...](\ref cub::BlockReduceAlgorithm)
* -# <b>cub::BLOCK_REDUCE_RAKING</b>. An efficient "raking" reduction algorithm that supports commutative and non-commutative reduction operators. [More...](\ref cub::BlockReduceAlgorithm)
* -# <b>cub::BLOCK_REDUCE_WARP_REDUCTIONS</b>. A quick "tiled warp-reductions" reduction algorithm that supports commutative and non-commutative reduction operators. [More...](\ref cub::BlockReduceAlgorithm)
*
* \par Performance Considerations
* - \granularity
* - Very efficient (only one synchronization barrier).
* - Incurs zero bank conflicts for most types
* - Computation is slightly more efficient (i.e., having lower instruction overhead) for:
* - Summation (<b><em>vs.</em></b> generic reduction)
* - \p BLOCK_THREADS is a multiple of the architecture's warp size
* - Every thread has a valid input (i.e., full <b><em>vs.</em></b> partial-tiles)
* - See cub::BlockReduceAlgorithm for performance details regarding algorithmic alternatives
*
* \par A Simple Example
* \blockcollective{BlockReduce}
xgboost/cub/cub/block/block_reduce.cuh view on Meta::CPAN
{
return InternalBlockReduce(temp_storage).template Reduce<true>(input, BLOCK_THREADS, reduction_op);
}
/**
* \brief Computes a block-wide reduction for thread<sub>0</sub> using the specified binary reduction functor. Each thread contributes an array of consecutive input elements.
*
* \par
* - The return value is undefined in threads other than thread<sub>0</sub>.
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a max reduction of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_reduce.cuh>
*
xgboost/cub/cub/block/block_reduce.cuh view on Meta::CPAN
T input) ///< [in] Calling thread's input
{
return InternalBlockReduce(temp_storage).template Sum<true>(input, BLOCK_THREADS);
}
/**
* \brief Computes a block-wide reduction for thread<sub>0</sub> using addition (+) as the reduction operator. Each thread contributes an array of consecutive input elements.
*
* \par
* - The return value is undefined in threads other than thread<sub>0</sub>.
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a sum reduction of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_reduce.cuh>
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
* that the <em>i</em><sup>th</sup> output reduction incorporates the <em>i</em><sup>th</sup> input.
* The term \em exclusive indicates the <em>i</em><sup>th</sup> input is not incorporated into
* the <em>i</em><sup>th</sup> output reduction.
* - \rowmajor
* - BlockScan can be optionally specialized by algorithm to accommodate different workload profiles:
* -# <b>cub::BLOCK_SCAN_RAKING</b>. An efficient (high throughput) "raking reduce-then-scan" prefix scan algorithm. [More...](\ref cub::BlockScanAlgorithm)
* -# <b>cub::BLOCK_SCAN_RAKING_MEMOIZE</b>. Similar to cub::BLOCK_SCAN_RAKING, but having higher throughput at the expense of additional register pressure for intermediate storage. [More...](\ref cub::BlockScanAlgorithm)
* -# <b>cub::BLOCK_SCAN_WARP_SCANS</b>. A quick (low latency) "tiled warpscans" prefix scan algorithm. [More...](\ref cub::BlockScanAlgorithm)
*
* \par Performance Considerations
* - \granularity
* - Uses special instructions when applicable (e.g., warp \p SHFL)
* - Uses synchronization-free communication between warp lanes when applicable
* - Invokes a minimal number of minimal block-wide synchronization barriers (only
* one or two depending on algorithm selection)
* - Incurs zero bank conflicts for most types
* - Computation is slightly more efficient (i.e., having lower instruction overhead) for:
* - Prefix sum variants (<b><em>vs.</em></b> generic scan)
* - \blocksize
* - See cub::BlockScanAlgorithm for performance details regarding algorithmic alternatives
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
*********************************************************************/
//@{
/**
* \brief Computes an exclusive block-wide prefix scan using addition (+) as the scan operator. Each thread contributes an array of consecutive input elements. The value of 0 is applied as the initial value, and is assigned to \p output[0] in <...
*
* \par
* - \identityzero
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates an exclusive prefix sum of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
ExclusiveScan(input, output, initial_value, cub::Sum());
}
/**
* \brief Computes an exclusive block-wide prefix scan using addition (+) as the scan operator. Each thread contributes an array of consecutive input elements. The value of 0 is applied as the initial value, and is assigned to \p output[0] in <...
*
* \par
* - \identityzero
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates an exclusive prefix sum of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
/**
* \brief Computes an exclusive block-wide prefix scan using addition (+) as the scan operator. Each thread contributes an array of consecutive input elements. Instead of using 0 as the block-wide prefix, the call-back functor \p block_prefix_c...
*
* \par
* - \identityzero
* - The \p block_prefix_callback_op functor must implement a member function <tt>T operator()(T block_aggregate)</tt>.
* The functor's input parameter \p block_aggregate is the same value also returned by the scan operation.
* The functor will be invoked by the first warp of threads in the block, however only the return value from
* <em>lane</em><sub>0</sub> is applied as the block-wide prefix. Can be stateful.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a single thread block that progressively
* computes an exclusive prefix sum over multiple "tiles" of input using a
* prefix functor to maintain a running total between block-wide scans. Each tile consists
* of 512 integer items that are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3)
* across 128 threads where each thread owns 4 consecutive items.
* \par
* \code
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
*********************************************************************/
//@{
/**
* \brief Computes an exclusive block-wide prefix scan using the specified binary \p scan_op functor. Each thread contributes an array of consecutive input elements.
*
* \par
* - Supports non-commutative scan operators.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates an exclusive prefix max scan of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
ThreadScanExclusive(input, output, scan_op, thread_prefix);
}
/**
* \brief Computes an exclusive block-wide prefix scan using the specified binary \p scan_op functor. Each thread contributes an array of consecutive input elements. Also provides every thread with the block-wide \p block_aggregate of all input...
*
* \par
* - Supports non-commutative scan operators.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates an exclusive prefix max scan of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
/**
* \brief Computes an exclusive block-wide prefix scan using the specified binary \p scan_op functor. Each thread contributes an array of consecutive input elements. the call-back functor \p block_prefix_callback_op is invoked by the first warp...
*
* \par
* - The \p block_prefix_callback_op functor must implement a member function <tt>T operator()(T block_aggregate)</tt>.
* The functor's input parameter \p block_aggregate is the same value also returned by the scan operation.
* The functor will be invoked by the first warp of threads in the block, however only the return value from
* <em>lane</em><sub>0</sub> is applied as the block-wide prefix. Can be stateful.
* - Supports non-commutative scan operators.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a single thread block that progressively
* computes an exclusive prefix max scan over multiple "tiles" of input using a
* prefix functor to maintain a running total between block-wide scans. Each tile consists
* of 128 integer items that are partitioned across 128 threads.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
*********************************************************************/
//@{
/**
* \brief Computes an exclusive block-wide prefix scan using the specified binary \p scan_op functor. Each thread contributes an array of consecutive input elements. With no initial value, the output computed for <em>thread</em><sub>0</sub> is ...
*
* \par
* - Supports non-commutative scan operators.
* - \blocked
* - \granularity
* - \smemreuse
*
* \tparam ITEMS_PER_THREAD <b>[inferred]</b> The number of consecutive items partitioned onto each thread.
* \tparam ScanOp <b>[inferred]</b> Binary scan functor type having member <tt>T operator()(const T &a, const T &b)</tt>
*/
template <
int ITEMS_PER_THREAD,
typename ScanOp>
__device__ __forceinline__ void ExclusiveScan(
T (&input)[ITEMS_PER_THREAD], ///< [in] Calling thread's input items
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
ThreadScanExclusive(input, output, scan_op, thread_partial, (linear_tid != 0));
}
/**
* \brief Computes an exclusive block-wide prefix scan using the specified binary \p scan_op functor. Each thread contributes an array of consecutive input elements. Also provides every thread with the block-wide \p block_aggregate of all input...
*
* \par
* - Supports non-commutative scan operators.
* - \blocked
* - \granularity
* - \smemreuse
*
* \tparam ITEMS_PER_THREAD <b>[inferred]</b> The number of consecutive items partitioned onto each thread.
* \tparam ScanOp <b>[inferred]</b> Binary scan functor type having member <tt>T operator()(const T &a, const T &b)</tt>
*/
template <
int ITEMS_PER_THREAD,
typename ScanOp>
__device__ __forceinline__ void ExclusiveScan(
T (&input)[ITEMS_PER_THREAD], ///< [in] Calling thread's input items
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
* \name Inclusive prefix sum operations (multiple data per thread)
*********************************************************************/
//@{
/**
* \brief Computes an inclusive block-wide prefix scan using addition (+) as the scan operator. Each thread contributes an array of consecutive input elements.
*
* \par
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates an inclusive prefix sum of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
ThreadScanInclusive(input, output, scan_op, thread_prefix, (linear_tid != 0));
}
}
/**
* \brief Computes an inclusive block-wide prefix scan using addition (+) as the scan operator. Each thread contributes an array of consecutive input elements. Also provides every thread with the block-wide \p block_aggregate of all inputs.
*
* \par
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates an inclusive prefix sum of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
/**
* \brief Computes an inclusive block-wide prefix scan using addition (+) as the scan operator. Each thread contributes an array of consecutive input elements. Instead of using 0 as the block-wide prefix, the call-back functor \p block_prefix_c...
*
* \par
* - The \p block_prefix_callback_op functor must implement a member function <tt>T operator()(T block_aggregate)</tt>.
* The functor's input parameter \p block_aggregate is the same value also returned by the scan operation.
* The functor will be invoked by the first warp of threads in the block, however only the return value from
* <em>lane</em><sub>0</sub> is applied as the block-wide prefix. Can be stateful.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a single thread block that progressively
* computes an inclusive prefix sum over multiple "tiles" of input using a
* prefix functor to maintain a running total between block-wide scans. Each tile consists
* of 512 integer items that are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3)
* across 128 threads where each thread owns 4 consecutive items.
* \par
* \code
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
*********************************************************************/
//@{
/**
* \brief Computes an inclusive block-wide prefix scan using the specified binary \p scan_op functor. Each thread contributes an array of consecutive input elements.
*
* \par
* - Supports non-commutative scan operators.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates an inclusive prefix max scan of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
}
}
/**
* \brief Computes an inclusive block-wide prefix scan using the specified binary \p scan_op functor. Each thread contributes an array of consecutive input elements. Also provides every thread with the block-wide \p block_aggregate of all input...
*
* \par
* - Supports non-commutative scan operators.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates an inclusive prefix max scan of 512 integer items that
* are partitioned in a [<em>blocked arrangement</em>](index.html#sec5sec3) across 128 threads
* where each thread owns 4 consecutive items.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
*
xgboost/cub/cub/block/block_scan.cuh view on Meta::CPAN
/**
* \brief Computes an inclusive block-wide prefix scan using the specified binary \p scan_op functor. Each thread contributes an array of consecutive input elements. the call-back functor \p block_prefix_callback_op is invoked by the first warp...
*
* \par
* - The \p block_prefix_callback_op functor must implement a member function <tt>T operator()(T block_aggregate)</tt>.
* The functor's input parameter \p block_aggregate is the same value also returned by the scan operation.
* The functor will be invoked by the first warp of threads in the block, however only the return value from
* <em>lane</em><sub>0</sub> is applied as the block-wide prefix. Can be stateful.
* - Supports non-commutative scan operators.
* - \blocked
* - \granularity
* - \smemreuse
*
* \par Snippet
* The code snippet below illustrates a single thread block that progressively
* computes an inclusive prefix max scan over multiple "tiles" of input using a
* prefix functor to maintain a running total between block-wide scans. Each tile consists
* of 128 integer items that are partitioned across 128 threads.
* \par
* \code
* #include <cub/cub.cuh> // or equivalently <cub/block/block_scan.cuh>
xgboost/cub/cub/block/block_shuffle.cuh view on Meta::CPAN
output = temp_storage[offset].prev;
}
/**
* \brief The thread block rotates its [<em>blocked arrangement</em>](index.html#sec5sec3) of \p input items, shifting it up by one item
*
* \par
* - \blocked
* - \granularity
* - \smemreuse
*/
template <int ITEMS_PER_THREAD>
__device__ __forceinline__ void Up(
T (&input)[ITEMS_PER_THREAD], ///< [in] The calling thread's input items
T (&prev)[ITEMS_PER_THREAD]) ///< [out] The corresponding predecessor items (may be aliased to \p input). The item \p prev[0] is not updated for <em>thread</em><sub>0</sub>.
{
temp_storage[linear_tid].prev = input[ITEMS_PER_THREAD - 1];
CTA_SYNC();
xgboost/cub/cub/block/block_shuffle.cuh view on Meta::CPAN
if (linear_tid > 0)
prev[0] = temp_storage[linear_tid - 1].prev;
}
/**
* \brief The thread block rotates its [<em>blocked arrangement</em>](index.html#sec5sec3) of \p input items, shifting it up by one item. All threads receive the \p input provided by <em>thread</em><sub><tt>BLOCK_THREADS-1</tt></sub>.
*
* \par
* - \blocked
* - \granularity
* - \smemreuse
*/
template <int ITEMS_PER_THREAD>
__device__ __forceinline__ void Up(
T (&input)[ITEMS_PER_THREAD], ///< [in] The calling thread's input items
T (&prev)[ITEMS_PER_THREAD], ///< [out] The corresponding predecessor items (may be aliased to \p input). The item \p prev[0] is not updated for <em>thread</em><sub>0</sub>.
T &block_suffix) ///< [out] The item \p input[ITEMS_PER_THREAD-1] from <em>thread</em><sub><tt>BLOCK_THREADS-1</tt></sub>, provided to all threads
{
Up(input, prev);
block_suffix = temp_storage[BLOCK_THREADS - 1].prev;
}
/**
* \brief The thread block rotates its [<em>blocked arrangement</em>](index.html#sec5sec3) of \p input items, shifting it down by one item
*
* \par
* - \blocked
* - \granularity
* - \smemreuse
*/
template <int ITEMS_PER_THREAD>
__device__ __forceinline__ void Down(
T (&input)[ITEMS_PER_THREAD], ///< [in] The calling thread's input items
T (&prev)[ITEMS_PER_THREAD]) ///< [out] The corresponding predecessor items (may be aliased to \p input). The value \p prev[0] is not updated for <em>thread</em><sub>BLOCK_THREADS-1</sub>.
{
temp_storage[linear_tid].prev = input[ITEMS_PER_THREAD - 1];
CTA_SYNC();
xgboost/cub/cub/block/block_shuffle.cuh view on Meta::CPAN
if (linear_tid > 0)
prev[0] = temp_storage[linear_tid - 1].prev;
}
/**
* \brief The thread block rotates its [<em>blocked arrangement</em>](index.html#sec5sec3) of input items, shifting it down by one item. All threads receive \p input[0] provided by <em>thread</em><sub><tt>0</tt></sub>.
*
* \par
* - \blocked
* - \granularity
* - \smemreuse
*/
template <int ITEMS_PER_THREAD>
__device__ __forceinline__ void Down(
T (&input)[ITEMS_PER_THREAD], ///< [in] The calling thread's input items
T (&prev)[ITEMS_PER_THREAD], ///< [out] The corresponding predecessor items (may be aliased to \p input). The value \p prev[0] is not updated for <em>thread</em><sub>BLOCK_THREADS-1</sub>.
T &block_prefix) ///< [out] The item \p input[0] from <em>thread</em><sub><tt>0</tt></sub>, provided to all threads
{
Up(input, prev);
block_prefix = temp_storage[BLOCK_THREADS - 1].prev;
xgboost/doc/model.md view on Meta::CPAN
We need to define the complexity of the tree ``$\Omega(f)$``. In order to do so, let us first refine the definition of the tree ``$ f(x) $`` as
```math
f_t(x) = w_{q(x)}, w \in R^T, q:R^d\rightarrow \{1,2,\cdots,T\} .
```
Here ``$ w $`` is the vector of scores on leaves, ``$ q $`` is a function assigning each data point to the corresponding leaf, and ``$ T $`` is the number of leaves.
In XGBoost, we define the complexity as
```math
\Omega(f) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2
```
Of course there is more than one way to define the complexity, but this specific one works well in practice. The regularization is one part most tree packages treat
less carefully, or simply ignore. This was because the traditional treatment of tree learning only emphasized improving impurity, while the complexity control was left to heuristics.
By defining it formally, we can get a better idea of what we are learning, and yes it works well in practice.
### The Structure Score
Here is the magical part of the derivation. After reformalizing the tree model, we can write the objective value with the ``$ t$``-th tree as:
```math
Obj^{(t)} &\approx \sum_{i=1}^n [g_i w_{q(x_i)} + \frac{1}{2} h_i w_{q(x_i)}^2] + \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2\\
&= \sum^T_{j=1} [(\sum_{i\in I_j} g_i) w_j + \frac{1}{2} (\sum_{i\in I_j} h_i + \lambda) w_j^2 ] + \gamma T
```
where ``$ I_j = \{i|q(x_i)=j\} $`` is the set of indices of data points assigned to the ``$ j $``-th leaf.
Notice that in the second line we have changed the index of the summation because all the data points on the same leaf get the same score.
We could further compress the expression by defining ``$ G_j = \sum_{i\in I_j} g_i $`` and ``$ H_j = \sum_{i\in I_j} h_i $``:
```math
\text{obj}^{(t)} = \sum^T_{j=1} [G_jw_j + \frac{1}{2} (H_j+\lambda) w_j^2] +\gamma T
```
In this equation ``$ w_j $`` are independent with respect to each other, the form ``$ G_jw_j+\frac{1}{2}(H_j+\lambda)w_j^2 $`` is quadratic and the best ``$ w_j $`` for a given structure ``$q(x)$`` and the best objective reduction we can get is:
```math
w_j^\ast = -\frac{G_j}{H_j+\lambda}\\
\text{obj}^\ast = -\frac{1}{2} \sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma T
```
The last equation measures ***how good*** a tree structure ``$q(x)$`` is.

If all this sounds a bit complicated, let's take a look at the picture, and see how the scores can be calculated.
Basically, for a given tree structure, we push the statistics ``$g_i$`` and ``$h_i$`` to the leaves they belong to,
sum the statistics together, and use the formula to calculate how good the tree is.
This score is like the impurity measure in a decision tree, except that it also takes the model complexity into account.
### Learn the tree structure
Now that we have a way to measure how good a tree is, ideally we would enumerate all possible trees and pick the best one.
In practice this is intractable, so we will try to optimize one level of the tree at a time.
Specifically we try to split a leaf into two leaves, and the score it gains is
```math
Gain = \frac{1}{2} \left[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}\right] - \gamma
```
This formula can be decomposed as 1) the score on the new left leaf 2) the score on the new right leaf 3) The score on the original leaf 4) regularization on the additional leaf.
We can see an important fact here: if the gain is smaller than ``$\gamma$``, we would do better not to add that branch. This is exactly the ***pruning*** techniques in tree based
models! By using the principles of supervised learning, we can naturally come up with the reason these techniques work :)
For real valued data, we usually want to search for an optimal split. To efficiently do so, we place all the instances in sorted order, like the following picture.
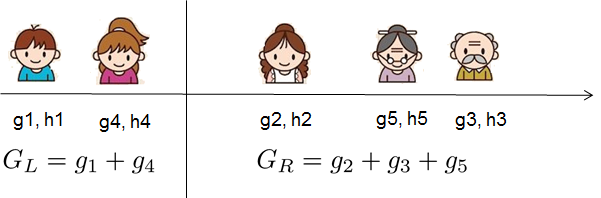
A left to right scan is sufficient to calculate the structure score of all possible split solutions, and we can find the best split efficiently.
Final words on XGBoost
----------------------
Now that you understand what boosted trees are, you may ask, where is the introduction on [XGBoost](https://github.com/dmlc/xgboost)?
xgboost/doc/tutorials/monotonic.md view on Meta::CPAN
A common type of constraint in this situation is that certain features bear a *monotonic* relationship to the predicted response:
```math
f(x_1, x_2, \ldots, x, \ldots, x_{n-1}, x_n) \leq f(x_1, x_2, \ldots, x', \ldots, x_{n-1}, x_n)
```
whenever ``$ x \leq x' $`` is an *increasing constraint*; or
```math
f(x_1, x_2, \ldots, x, \ldots, x_{n-1}, x_n) \geq f(x_1, x_2, \ldots, x', \ldots, x_{n-1}, x_n)
```
whenever ``$ x \leq x' $`` is a *decreasing constraint*.
XGBoost has the ability to enforce monotonicity constraints on any features used in a boosted model.
A Simple Example
----------------
To illustrate, let's create some simulated data with two features and a response according to the following scheme