Alien-XGBoost
view release on metacpan or search on metacpan
xgboost/dmlc-core/doc/Doxyfile view on Meta::CPAN
# The SYMBOL_CACHE_SIZE determines the size of the internal cache use to
# determine which symbols to keep in memory and which to flush to disk.
# When the cache is full, less often used symbols will be written to disk.
# For small to medium size projects (<1000 input files) the default value is
# probably good enough. For larger projects a too small cache size can cause
# doxygen to be busy swapping symbols to and from disk most of the time
# causing a significant performance penalty.
# If the system has enough physical memory increasing the cache will improve the
# performance by keeping more symbols in memory. Note that the value works on
# a logarithmic scale so increasing the size by one will roughly double the
# memory usage. The cache size is given by this formula:
# 2^(16+SYMBOL_CACHE_SIZE). The valid range is 0..9, the default is 0,
# corresponding to a cache size of 2^16 = 65536 symbols.
SYMBOL_CACHE_SIZE = 0
# Similar to the SYMBOL_CACHE_SIZE the size of the symbol lookup cache can be
# set using LOOKUP_CACHE_SIZE. This cache is used to resolve symbols given
# their name and scope. Since this can be an expensive process and often the
# same symbol appear multiple times in the code, doxygen keeps a cache of
# pre-resolved symbols. If the cache is too small doxygen will become slower.
# If the cache is too large, memory is wasted. The cache size is given by this
# formula: 2^(16+LOOKUP_CACHE_SIZE). The valid range is 0..9, the default is 0,
# corresponding to a cache size of 2^16 = 65536 symbols.
LOOKUP_CACHE_SIZE = 0
#---------------------------------------------------------------------------
# Build related configuration options
#---------------------------------------------------------------------------
# If the EXTRACT_ALL tag is set to YES doxygen will assume all entities in
# documentation are documented, even if no documentation was available.
xgboost/dmlc-core/doc/Doxyfile view on Meta::CPAN
# used to set the initial width (in pixels) of the frame in which the tree
# is shown.
TREEVIEW_WIDTH = 250
# When the EXT_LINKS_IN_WINDOW option is set to YES doxygen will open
# links to external symbols imported via tag files in a separate window.
EXT_LINKS_IN_WINDOW = NO
# Use this tag to change the font size of Latex formulas included
# as images in the HTML documentation. The default is 10. Note that
# when you change the font size after a successful doxygen run you need
# to manually remove any form_*.png images from the HTML output directory
# to force them to be regenerated.
FORMULA_FONTSIZE = 10
# Use the FORMULA_TRANPARENT tag to determine whether or not the images
# generated for formulas are transparent PNGs. Transparent PNGs are
# not supported properly for IE 6.0, but are supported on all modern browsers.
# Note that when changing this option you need to delete any form_*.png files
# in the HTML output before the changes have effect.
FORMULA_TRANSPARENT = YES
# Enable the USE_MATHJAX option to render LaTeX formulas using MathJax
# (see http://www.mathjax.org) which uses client side Javascript for the
# rendering instead of using prerendered bitmaps. Use this if you do not
# have LaTeX installed or if you want to formulas look prettier in the HTML
# output. When enabled you also need to install MathJax separately and
# configure the path to it using the MATHJAX_RELPATH option.
USE_MATHJAX = NO
# When MathJax is enabled you need to specify the location relative to the
# HTML output directory using the MATHJAX_RELPATH option. The destination
# directory should contain the MathJax.js script. For instance, if the mathjax
# directory is located at the same level as the HTML output directory, then
# MATHJAX_RELPATH should be ../mathjax. The default value points to the
xgboost/dmlc-core/doc/Doxyfile view on Meta::CPAN
# The LATEX_OUTPUT tag is used to specify where the LaTeX docs will be put.
# If a relative path is entered the value of OUTPUT_DIRECTORY will be
# put in front of it. If left blank `latex' will be used as the default path.
LATEX_OUTPUT = latex
# The LATEX_CMD_NAME tag can be used to specify the LaTeX command name to be
# invoked. If left blank `latex' will be used as the default command name.
# Note that when enabling USE_PDFLATEX this option is only used for
# generating bitmaps for formulas in the HTML output, but not in the
# Makefile that is written to the output directory.
LATEX_CMD_NAME = latex
# The MAKEINDEX_CMD_NAME tag can be used to specify the command name to
# generate index for LaTeX. If left blank `makeindex' will be used as the
# default command name.
MAKEINDEX_CMD_NAME = makeindex
xgboost/dmlc-core/doc/Doxyfile view on Meta::CPAN
# If the USE_PDFLATEX tag is set to YES, pdflatex will be used instead of
# plain latex in the generated Makefile. Set this option to YES to get a
# higher quality PDF documentation.
USE_PDFLATEX = YES
# If the LATEX_BATCHMODE tag is set to YES, doxygen will add the \\batchmode.
# command to the generated LaTeX files. This will instruct LaTeX to keep
# running if errors occur, instead of asking the user for help.
# This option is also used when generating formulas in HTML.
LATEX_BATCHMODE = NO
# If LATEX_HIDE_INDICES is set to YES then doxygen will not
# include the index chapters (such as File Index, Compound Index, etc.)
# in the output.
LATEX_HIDE_INDICES = NO
# If LATEX_SOURCE_CODE is set to YES then doxygen will include
xgboost/doc/Doxyfile view on Meta::CPAN
# types are typedef'ed and only the typedef is referenced, never the tag name.
# The default value is: NO.
TYPEDEF_HIDES_STRUCT = NO
# The size of the symbol lookup cache can be set using LOOKUP_CACHE_SIZE. This
# cache is used to resolve symbols given their name and scope. Since this can be
# an expensive process and often the same symbol appears multiple times in the
# code, doxygen keeps a cache of pre-resolved symbols. If the cache is too small
# doxygen will become slower. If the cache is too large, memory is wasted. The
# cache size is given by this formula: 2^(16+LOOKUP_CACHE_SIZE). The valid range
# is 0..9, the default is 0, corresponding to a cache size of 2^16=65536
# symbols. At the end of a run doxygen will report the cache usage and suggest
# the optimal cache size from a speed point of view.
# Minimum value: 0, maximum value: 9, default value: 0.
LOOKUP_CACHE_SIZE = 0
#---------------------------------------------------------------------------
# Build related configuration options
#---------------------------------------------------------------------------
xgboost/doc/Doxyfile view on Meta::CPAN
TREEVIEW_WIDTH = 250
# When the EXT_LINKS_IN_WINDOW option is set to YES doxygen will open links to
# external symbols imported via tag files in a separate window.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
EXT_LINKS_IN_WINDOW = NO
# Use this tag to change the font size of LaTeX formulas included as images in
# the HTML documentation. When you change the font size after a successful
# doxygen run you need to manually remove any form_*.png images from the HTML
# output directory to force them to be regenerated.
# Minimum value: 8, maximum value: 50, default value: 10.
# This tag requires that the tag GENERATE_HTML is set to YES.
FORMULA_FONTSIZE = 10
# Use the FORMULA_TRANPARENT tag to determine whether or not the images
# generated for formulas are transparent PNGs. Transparent PNGs are not
# supported properly for IE 6.0, but are supported on all modern browsers.
#
# Note that when changing this option you need to delete any form_*.png files in
# the HTML output directory before the changes have effect.
# The default value is: YES.
# This tag requires that the tag GENERATE_HTML is set to YES.
FORMULA_TRANSPARENT = YES
# Enable the USE_MATHJAX option to render LaTeX formulas using MathJax (see
# http://www.mathjax.org) which uses client side Javascript for the rendering
# instead of using prerendered bitmaps. Use this if you do not have LaTeX
# installed or if you want to formulas look prettier in the HTML output. When
# enabled you may also need to install MathJax separately and configure the path
# to it using the MATHJAX_RELPATH option.
# The default value is: NO.
# This tag requires that the tag GENERATE_HTML is set to YES.
USE_MATHJAX = NO
# When MathJax is enabled you can set the default output format to be used for
# the MathJax output. See the MathJax site (see:
# http://docs.mathjax.org/en/latest/output.html) for more details.
xgboost/doc/Doxyfile view on Meta::CPAN
# it.
# The default directory is: latex.
# This tag requires that the tag GENERATE_LATEX is set to YES.
LATEX_OUTPUT = latex
# The LATEX_CMD_NAME tag can be used to specify the LaTeX command name to be
# invoked.
#
# Note that when enabling USE_PDFLATEX this option is only used for generating
# bitmaps for formulas in the HTML output, but not in the Makefile that is
# written to the output directory.
# The default file is: latex.
# This tag requires that the tag GENERATE_LATEX is set to YES.
LATEX_CMD_NAME = latex
# The MAKEINDEX_CMD_NAME tag can be used to specify the command name to generate
# index for LaTeX.
# The default file is: makeindex.
# This tag requires that the tag GENERATE_LATEX is set to YES.
xgboost/doc/Doxyfile view on Meta::CPAN
# the PDF file directly from the LaTeX files. Set this option to YES to get a
# higher quality PDF documentation.
# The default value is: YES.
# This tag requires that the tag GENERATE_LATEX is set to YES.
USE_PDFLATEX = YES
# If the LATEX_BATCHMODE tag is set to YES, doxygen will add the \batchmode
# command to the generated LaTeX files. This will instruct LaTeX to keep running
# if errors occur, instead of asking the user for help. This option is also used
# when generating formulas in HTML.
# The default value is: NO.
# This tag requires that the tag GENERATE_LATEX is set to YES.
LATEX_BATCHMODE = NO
# If the LATEX_HIDE_INDICES tag is set to YES then doxygen will not include the
# index chapters (such as File Index, Compound Index, etc.) in the output.
# The default value is: NO.
# This tag requires that the tag GENERATE_LATEX is set to YES.
xgboost/doc/README view on Meta::CPAN
The documentation of xgboost is generated with recommonmark and sphinx.
You can build it locally by typing "make html" in this folder.
- clone https://github.com/tqchen/recommonmark to root
- type make html
Checkout https://recommonmark.readthedocs.org for guide on how to write markdown with extensions used in this doc, such as math formulas and table of content.
xgboost/doc/model.md view on Meta::CPAN
```math
w_j^\ast = -\frac{G_j}{H_j+\lambda}\\
\text{obj}^\ast = -\frac{1}{2} \sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma T
```
The last equation measures ***how good*** a tree structure ``$q(x)$`` is.

If all this sounds a bit complicated, let's take a look at the picture, and see how the scores can be calculated.
Basically, for a given tree structure, we push the statistics ``$g_i$`` and ``$h_i$`` to the leaves they belong to,
sum the statistics together, and use the formula to calculate how good the tree is.
This score is like the impurity measure in a decision tree, except that it also takes the model complexity into account.
### Learn the tree structure
Now that we have a way to measure how good a tree is, ideally we would enumerate all possible trees and pick the best one.
In practice this is intractable, so we will try to optimize one level of the tree at a time.
Specifically we try to split a leaf into two leaves, and the score it gains is
```math
Gain = \frac{1}{2} \left[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}\right] - \gamma
```
This formula can be decomposed as 1) the score on the new left leaf 2) the score on the new right leaf 3) The score on the original leaf 4) regularization on the additional leaf.
We can see an important fact here: if the gain is smaller than ``$\gamma$``, we would do better not to add that branch. This is exactly the ***pruning*** techniques in tree based
models! By using the principles of supervised learning, we can naturally come up with the reason these techniques work :)
For real valued data, we usually want to search for an optimal split. To efficiently do so, we place all the instances in sorted order, like the following picture.
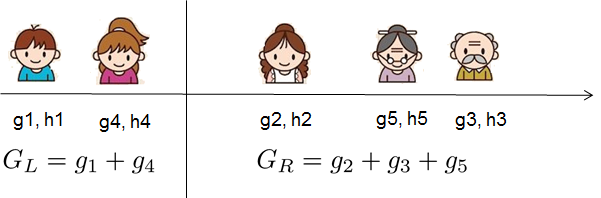
A left to right scan is sufficient to calculate the structure score of all possible split solutions, and we can find the best split efficiently.
Final words on XGBoost
----------------------
( run in 1.351 second using v1.01-cache-2.11-cpan-39bf76dae61 )